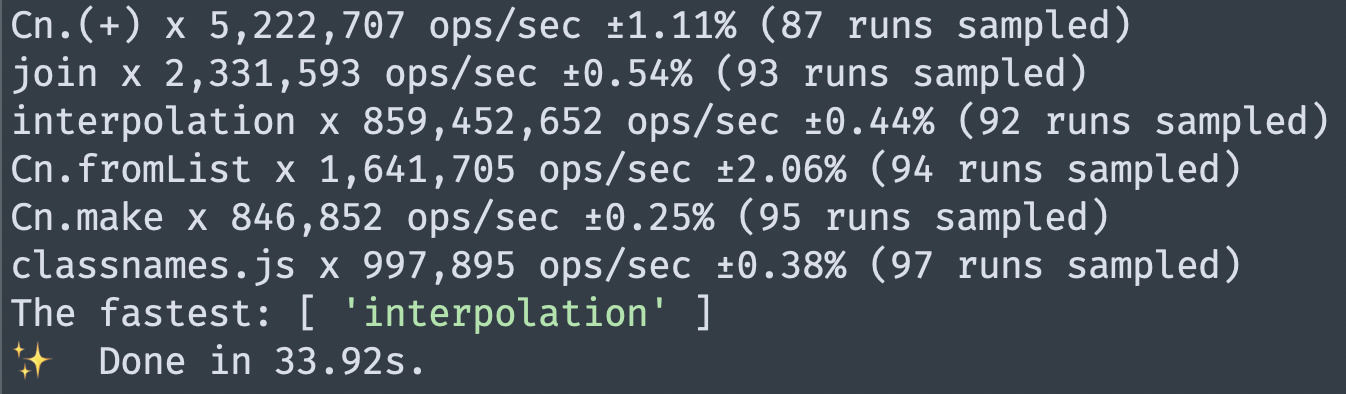
Join is third best and interpolation the obvious best. So yeah it’s not too surprising! But at this point the benchmark isn’t even accurate anymore because most of the conditions have been eliminated (or in a sense, actually more accurate of real-work workloads now).
A little bit of history: I was the original maintainer of the React classnames package before handing it to someone else who later heavily regretted spinning the API out of control. I think we have a chance to get back to the basics here and just join/interpolate. The simplicity will be a refreshing step up from the JS React ecosystem I believe.
I did manage to fully upgrade my package to the new ReScript syntax. It’s been great so far! The formatting is so much better than ReasonML ever way. It’s a much cleaner syntax too!
@chenglou This looks good to me. The only question is if infix api should be preserved in rescript-classnames since it’s as twice as fast as join. I mean it might be confusing for some new comers but providing option that is 2x faster for free for those who prefer using this utility and comfortable using infixes is ok imo. Mind I create a separate poll to get the community feedback?
I’m not sure this makes sense. I think after looking through the examples, it’s clear that join is the the easiest api for newcomers and if you are doing advanced things for performance then you should be doing interpolation. The infix api exists in an awkward middle ground where it’s orders of magnitude worse than best possible perf and also harder to read than an option that is same order of magnitude perf-wise.
Btw I’m rather positive (as I was positive about + being faster in my post before the benchmarks) that the + speed doesn’t translate into actual code speed, because there’s a large difference giving the JIT the same function a bajillion times vs interspersed a few times here and there in a codebase, not to mention the associated learning overhead. Also, interpolation is like 170x faster in synthetic and likely still faster in real-world. And the output of both alternatives are really important.
This is a tangent but for interpolation, we might have some extra nice things planned. Stay tuned.
@chenglou@rickyvetter Sorry, I didn’t look at the join implementation close enough. Apparently, it produces the same output with multiple spaces as interpolation except it’s 350+ times slower. I kinda don’t see a point in join at all?
Where do you see that 350x slowdown lol.
Also I can just paste you a join that does clean up spaces. Here’s a random one:
let join = arr => {
let result = ref("")
for (i in 0 to Js.Array2.length(arr) - 1) {
switch (Js.Array2.unsafe_get(arr, i)) {
| "" => ()
| name => result := i == 0 ? name : result.contents ++ " " ++ name
}
}
result.contents
}
Aaah yeah sorry for the confusion. I meant something like that. Basically a quick loop over the array concatenating non-empty strings.
Since this seems settled, I’d like to add 2 addendums which are imo practically and spiritually important:
For this use-case, I’d avoid using option from a state perspective. If you use an option then you’ve accidentally got yourself an extra Some("") that might cause bugs. Basically you end up with 3 states: Some(actualClassname), Some("") and None. Using more combinators would have hidden those deeper (in fact, the readme examples don’t catch that, simply because e.g. Some(emptyString)->take benignly hid this problem, now you end up debugging a funny empty string problem somewhere else in the codebase).
For classnames you’re aiming for 2 states: actualClassname and "". This is akin to what I’ve said in the big DOM thread; folks gotta be careful putting the cart before the horse trying to use combinators and other features and end up with a higher bug rate, higher cognitive rate and a higher confidence (“because FP concept!”). We’ve had to deal with many such bugs internally, including a double digit amount of exactly Some("").
A situation where you actually want tri-state is e.g. profile nickname, where you explicitly distinguish between no nickname, an empty nickname and a nonempty nickname.
At the end of the day, we need to realize that we’re doing string juggling only because HTML preferred the syntax sugar of a string DSL for classnames instead of a proper array, or in the case of HTML/XML, some admittedly unwieldy <names><value>flex</value><value>col-3</value></names>.
It’s ironic because that DSL gymnastic ended up fostering the wrong mental model for classnames, which in turn gave the wrong mental model here of using various tricks instead of treating the problem as what it is: specifying an array of strings or ids. Thus the FP <-> production disconnect we often see (at this point we’ve come back full circle to the thread’s topic). So yeah, going back to a boring array of strings is the right thing to do. That, and interpolation, which isn’t the most correct but definitely has the shortest amount of mental translation distance, which itself is worth a lot.