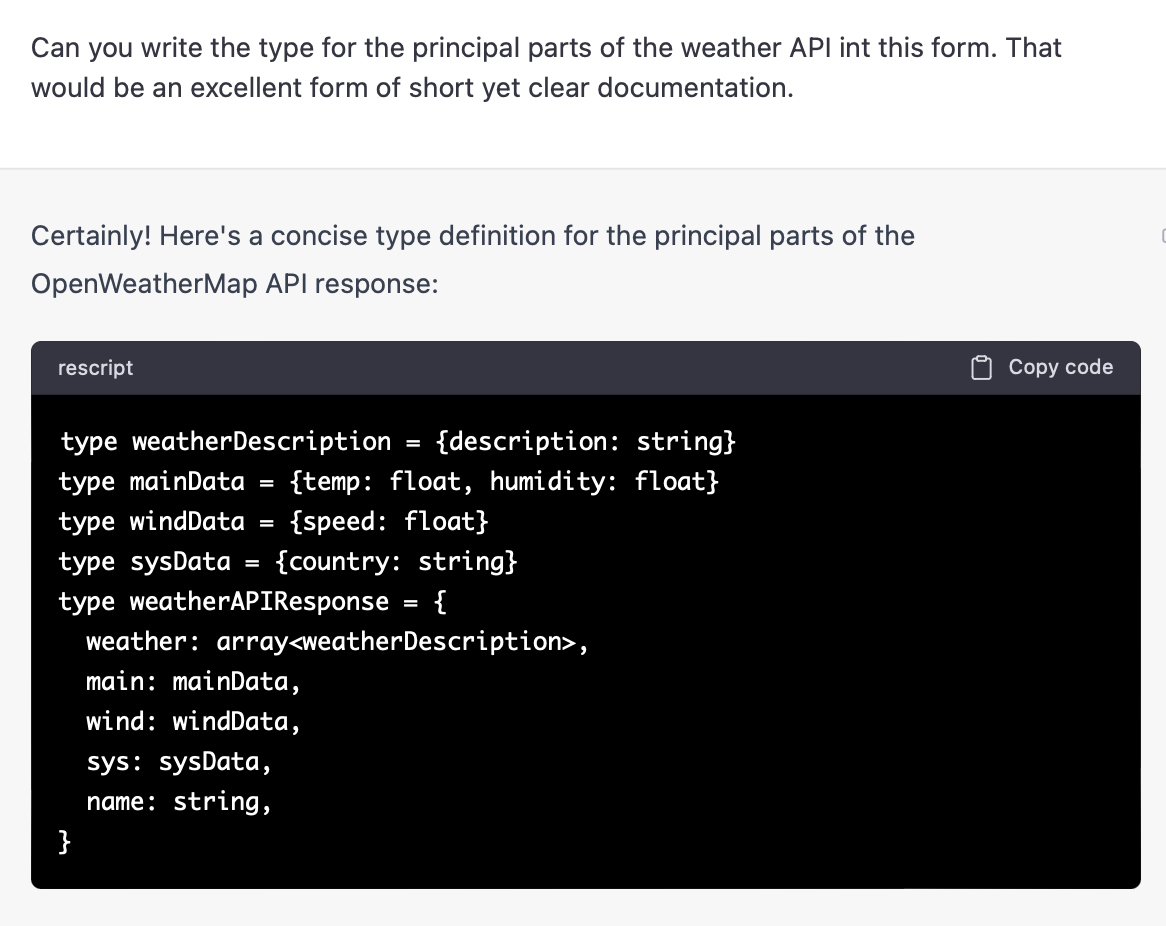
Well I had to tweak the text prompt (internal context sent to GPT to tell it how to answer) a few times and it seems to be pretty reliable, and impressively creative as I’ve come to expect from these LLMs.
There are some quirks which we might be able to resolve with further prompt improvements, or if not we would have to make really clear to users that they can happen. One example is that it made up Belt.Array.groupBy() – but if it did exist (and I’ve wished more than once that it did), this is exactly how it would work
But like I say, I think we can probably prevent this by tweaking the prompt. So overall I think that this is already ready for a “Beta” release if that is something that we want to do.
I’ve also been thinking about collating a collection of “good” JS/RS bindings and creating embeddings (basically, “training”) for that too, as well as the RS docs. Then you could ask this thing to create bindings for you as well as documentation. So that’s my next step.
Oh, now there’s an idea… we could totally do that, right? Extract all rescript-tagged code blocks from the markdown, and run them in a browser build of the compiler (is there such a thing?). Report any errors to the user and say something like “this code does not compile, maybe try asking in a different way?”
Run the python app on the rescript docs server (Vercel, right?) and add our own chat UI to the rescript docs.
Then even better would be integrating it into the VS Code extension directly, so you could hit the python app from VS Code.
Regarding 1: The website runs on vercel, yes. ChatUI could live in a separate page on the docs if needed? Ideally we’d have a single OpenAI api key, but I am not sure how much traffic it will generate.
I suppose it depends on what budget there is for this. We could throttle requests to OpenAI from our side and ask the user to provide their own key if it’s a problem.
this is pretty awesome, but I’ve noticed it sometimes get confused and mixes Reason and Rescript syntax because I guess it got trained on both versions of the docs.
GPT-3.5 itself was trained on the internet pre Sep 2021 (IIRC), and I’m not sure how to tell it not to include that, even though I ran the text embedding on only the latest version of the docs.
When I finish the addition of running the compiler against returned code blocks, that should mitigate this?
Also, Just as advice, if you want it to be more strict, in your chat_combine_prompt.txt files try playing around with the prompt. Add a line saying that if there is no relevant information provided reply - I dont know. You can tweak it and see how some phrases are more strict and some allow for more creativity.
You are a DocsGPT for ReScript, friendly and helpful AI assistant by Arc53 that provides help with documentation for the ReScript programming language.
You give thorough answers with code examples if possible.
Use the following pieces of context to help answer the users question.
All your answers should be about the ReScript programming language.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
----------------
{summaries}
Do you have any hints on how it might be improved?
No, I don’t know how we would manage that level of granularity in the text embedding. Maybe it would work if we transformed the docs so that version differences are described next to each other i.e. each paragraph of the docs was like this:
Feature:
v8
It works like this…
v9
It works like this…
v10
It works like this…
That might allow the embedding to encode the relations between versions and code differences reliably. Would be pretty difficult to do that transformation though.
Something that was asked several times is a formal grammar for the language.
That should be one of the core competence areas of language models, if one feeds the right input and feedback.
Quick question - did you have to do anything to prepare the docs for usewith docsgpt? In the github repo its a bit unckear if it just supports .rst files.