We don’t.
This is one of the first cases we considered. The ides for type variables, is to only accept at most 1 case with type variables in the definition. The alternatives would be way too complicated/inefficient to consider.
What’s interesting is that even with this restriction, untagged variants can encode quite a lot. Here are some reflections that were not included in the proposal above to avoid confusing people:
Appendix B: Encoding Tagged Variants Using Untagged Ones
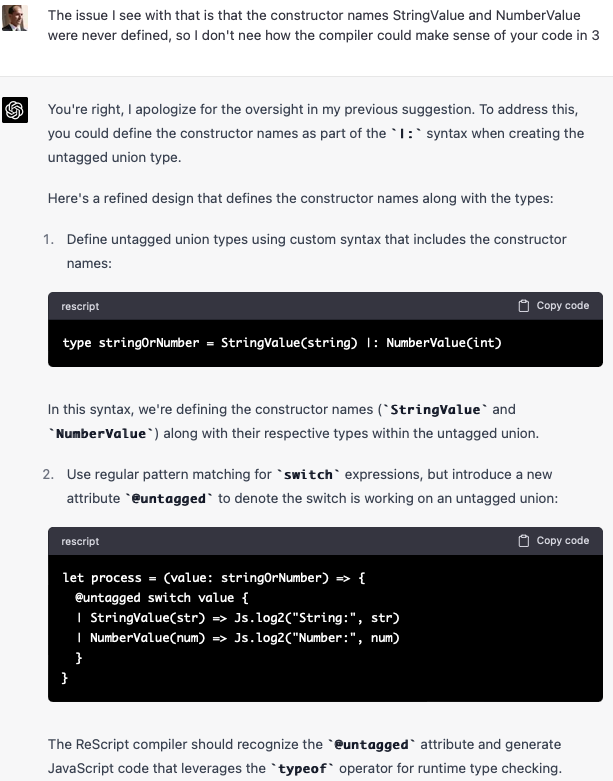
In this conversation, we discussed the possibility of representing tagged variants using untagged ones. While it is possible to do so, it introduces verbosity and requires the user to manage the tags manually. Users need to create and maintain the object types for each case and ensure the tag property is set correctly.
In contrast, native tagged variants are more concise and less error-prone, as the language handles tagging internally. Additionally, pattern matching syntax is more ergonomic when working with tagged variants, since it is designed explicitly for that purpose.
Although it is technically possible to represent tagged variants using untagged ones, it may not be the most convenient or efficient way to work with them in practice. The benefits of using native tagged variants in terms of conciseness, ease of use, and pattern matching support typically outweigh the advantages of using untagged variants for this purpose.
Appendix C: Encoding Polymorphic Variants Using Untagged Variants
In this conversation, we explored the possibility of encoding polymorphic variants using untagged variants, focusing on their extensibility and expressiveness. Untagged variants differ from polymorphic variants in that they rely on runtime type information and structure of the values, instead of using tags to distinguish cases.
Untagged variants can express extensibility in a tag-less manner by including a case with a type variable as payload. This allows the type to be extended with new cases without modifying the original type definition. Here’s an example:
type untaggedFruit<'a> =
|: Apple({ color: string })
|: Banana({ length: int })
|: Extra('a)
In this example, the Extra case with the type variable 'a enables the extensibility of the untaggedFruit type. By providing the appropriate payload type, we can extend the type with new cases, as shown in the example with the Orange case.
Untagged variants are strictly more expressive than polymorphic variants, as they can model tag-less, extensible types without relying on tags. However, this approach comes with trade-offs, such as potential performance implications and less concise pattern-matching syntax compared to polymorphic variants.