I get the attraction of keeping things simple/fast/zero-cost. You don’t have to use decoders. Just assume the JSON is the right shape and use it directly. Catch any exceptions that might get thrown. But also remember that some things like property accesses won’t throw exceptions for missing properties, they’ll return undefined. So maybe handle those specially using option types.
Now you have all these special rules that are encoded implicitly throughout the code. The possible error pathways aren’t reflected in the types. It makes it difficult to refactor and change code. This is what it means to lose type safety. I know that type safety is not a goal, just a means. But the ability to change code quickly and safely without breaking it, is a goal. And that’s what type safety enables.
On the other hand, performance and small bundle size is not a goal on its own; it is also a means to an end (good user experience). The user may be happier with a slightly heavier app that can guarantee no runtime crashes. And developers may also be happier with apps that don’t set off pagers. It’s all trade-offs
My 2 centavos: decoders give you the ability to actually trust your types. To make away with defensive programming (which might as well add more bloat to your bundle than decoders) and not be afraid of crashes or, worse, sublte bugs in unexpected places.
There’s also a bonus of having a specific place to deal with data errors and degrade gracefully (again, as opposed to doing it all over your app).
No matter how thorough your decoders are, they will do some assumptions at some point. Just consider any insane (but really common) use-case of having enormous monolithic REST endpoints, with completely wild (non-)specifications.
Let’s break down a very real, actual existing project and try to access data from existing endpoints. If this doesn’t get the point across, there is no point continuing this conversation.
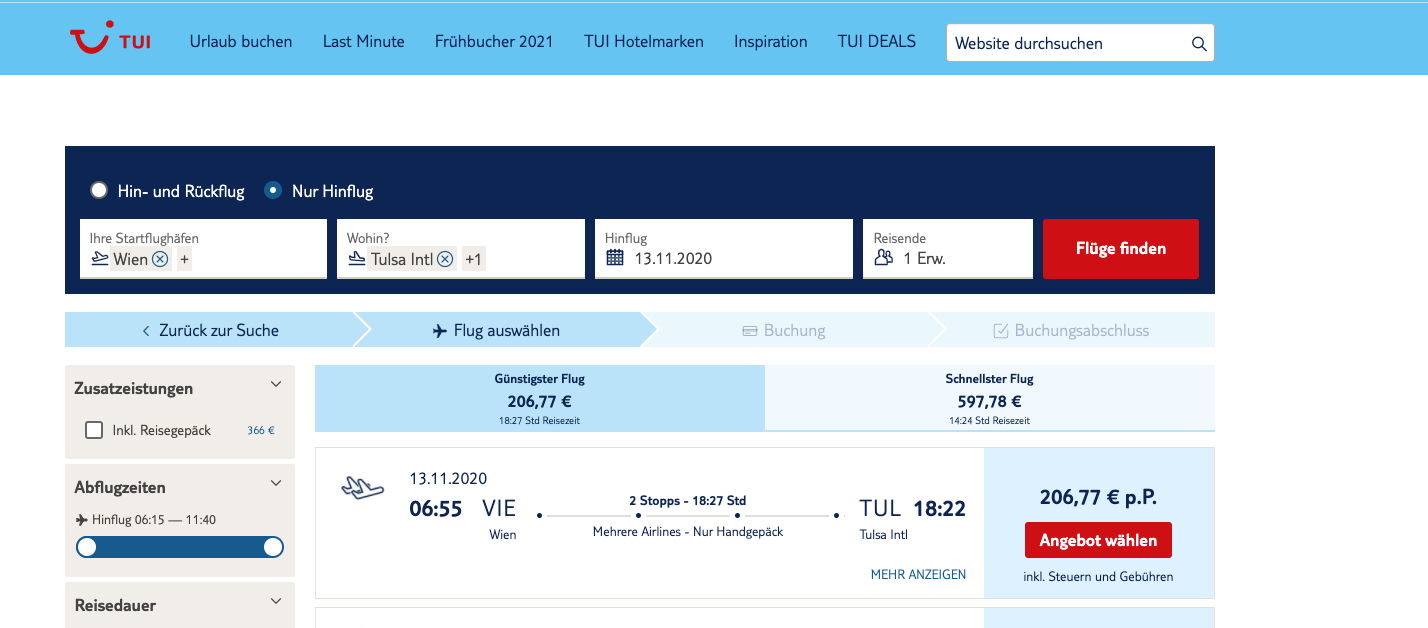
TUI.com has a really big search API for looking for vacation offers. Let’s assume I am a user that tries to find the best offers for a travel from Vienna to Tulsa:
First of all, finding out the spec, let alone going through all the organizational hierarchies within TUI to get to a single person who can tell you with 100% confidence what the actual spec is (in reality, nobody knows what they are doing, we are all in the impression that folks have a clear spec on their endpoints, reality reflects a different state, I am afraid).
Okay, so the strategy would be to “figure out the spec ourselves” by querying some endpoints and figuring out some system:
“Ah, this seems like a travel location structure”
“oh, and there are some coupon structures”
“seems like this search uses all those prev defined location structures in the target_locations attribute”
So you have been spending probably days to figure out your perfect types. Now you generate an INSANE amount of code via ppxes, first of all, completely wrecking our wonderful compile times, because these ppxes will cost you a lot of computation power on each file change, depending on how often you use the ppx in different files. We have seen massive additional compilation times caused by graphql_ppx btw.
Second of all, all this code will opaquely translate into even more massive amounts of JS code. And the best part: Most of the data in this massive 12k lines json object is absolutely useless. We only need some small fraction of it (yes, graphql yada yada, but this is an old project, and we are all dealing with legacy code / badly designed rest endpoints in 80% the cases, at least in Europe).
We are not even sure if our assumptions were correct! It’s completely ridiculous. Your coworkers will go in the code and be like “yeah we got all our types in place, so we are 100% safe”, which certainly is not true. It’s even worse, because we have wasted so much of our valuable time finding out the right structure (because through organizational reasons we can’t “just generate our schema”).
BTW the idea of validating types during runtime are not new. There are things like Flow runtime or Flow tcomp, or TypeScript runtypes. Guess what? These things don’t find any adoption because it’s mostly an intellectual exercise that can’t withhold a real world scenario in an all applicable manner or only work for very small scoped / niche project organizations… graphql is probably the most realistic system that could make “typed interfaces” work, but this of course also comes with drawbacks.
Conclusion
So what I am trying to say is that “just spec’ing your endpoints and generate the types”, whereas the UI is based on structural typing (therefore having an infinite amount of permutations of different record types), is an unrealistic goal, and we really think that skipping the whole type spec & generation part and instead go into our assumption based system that gets fine-tuned as we find errors in our integration / acceptance tests, is a way more realistic and easier way to handle the application boundaries. It’s also way easier for like 90% of the projects to adopt ReScript and enjoy all the other features that actually make ReScript enjoyable.
I hope you understand what I am saying. Seriously, whoever thinks that this is something any newcomer should do by default when coming into the ReScript community should probably do some consulting work and dive into different projects and organizations to get a clearer picture of how everyone is building their systems.
Decoders can be an optional solution decided case by case … like companies that set their goals to have fully spec’ed and fully type safe communication between client and server. Those companies that require 100% certainty and design their systems that way, and are willing to take those extra computational costs and are fine with certain bad UX scenarios (like slow loading UI etc).
I used the graphql_ppx for some smaller deployed projects (namely leiwand-kochen.at and diemagischezehn.at) to get an idea on its usage with different CMS platforms. Most of the time I am dealing with REST endpoints though, so I can’t really say anything about larger GraphQL based apps.
If you are referring to my statements regarding compilation times w/ 3rd party ppxes, i once published a benchmark-script for ReScript based projects and tried it on different open source projects (such as pupilfirst) that lead to my observations.
Feel free to try it on your own project. It’s not specifically aiming for graphql_ppx, but for ppxes in general. The more you use, the slower your build.
GraphQL is a great fit with Reason because we have a typed protocol. No need to write decoders and if you use the Query.Raw.t it’s even zero-cost (when performance is an issue), otherwise a very small conversion because the ReScript types map quite well.
This really makes Reason super productive AND typesafe. The main benefit of Reason/ReScript compared to TypeScript is that the source of most bugs for us was a mismatch between data a component expects and what it gets (even with GraphQL, it’s easy to forget to include a field in a fragment or to forget that a field is nullable).
graphql-ppx does make the build a little slower, but mostly because it does work that is valuable. Due to native tooling it’s still incredibly fast. My benchmarking is that it’s an order of magnitude faster than ReScript in most files that contain queries (so it mainly makes builds slower because it produces code that you didn’t have to write yourself). (Otherwise you’d have to type your whole query - and still have crashes because typing by hand is error prone).
I heard some people talk about this but never seen actual reproduction of it with recent version s of graphql-ppx. So mostly FUD. And otherwise I’d happy to help diagnose!
If you deal with a lot of REST, ReScript is not great tbh, that is one of the weak points of this language, but it really shines when you have a typed data layer like GraphQL combined with graphql-ppx. The great thing is that GraphQL is becoming ubiquitous.
BTW if you are on a legacy REST stack, in my opinion the best way to interface with them is to just write the data types as records just like you would write externals (and only include the fields that you need). I think that is kind of the point @ryyppy is making. (But I havent dealt with REST in years on the frontend - fortunate position, I know).
I’ve been in similar situations to the one you describe (where you cannot get proper specs for what you get), although not at that scale.
Well, here’s the deal with the manually written types and decoders: you can write them on per-need basis and ignore the rest. So maybe, and especially for third-party APIs with massive amount of data, manually written decoders strike a better balance. Same as JS libs interop, actually: you write bindings for what you need, not for everything that is there.
I guess my point is, even situations where “spec your endpoints and generate the types” don’t make sense don’t mean you should go by assumptions alone, becase fine-tuning things "as you find errors” might be easier if your data goes through decoders (you can log decoding errors etc.). I mean, if you write them manually, decoders are assumptions, so why not fine-tune them.
BTW we have an app on ReScript and graphql-ppx that has a near zero crash rating . Crashes were really a large concern before the introduction of ReScript and graphql-ppx (even with TypeScript). Especially if you have an app in the app store that needs to pass review before a bug can be fixed. So a typesafe data layer is worth something!
For REST there is the great atdgen. We use a little script to convert JSON-schema to .atd and adtgen creates the types/decoders/encoders. So backend and frontend (sitting in a monorepo) always have the same “contract”.
The only problem is, you have to learn a separate language (ATD) which is not even OCaml (but very similar). It would be nice to have something like this in a ReScript syntax, or even one step further, directly converting JSON-schema to .res/.resi.
If you have a specific case you can open a topic for sure, happy to dive in performance issue(s) with specific queries. I just wanted to react to the unfounded claims about graphql-ppx that I saw in your post.
Of course, different scenarios call for different concrete solutions. Here are some factors to consider:
If we have a massive data structure (and this was pointed out earlier), we’re almost never going to decode the entire structure, we’re going to walk through it to find only the parts we’re interested in. Decoders can generate that code instead of writing it by hand
Generated JS size may be an issue, but imho a well-designed solution (for the travel deal search scenario) is not going to be doing this deal search on the client side; it’s going to be on the server. So the user would never notice
PPXs may slow down compilation but I bet what slows it down even more is not using interface files. Without an interface file, the compiler has to calculate the effective interface (.resi/.rei/.mli) of every source file by first recompiling the implementation (.res/.re/.ml) file, every time the implementation is touched. With an explicit interface file, the compiler recompiles it only if the interface is changed. For best results, also turn on -opaque during development and the compiler will be even more aggressive about this [EDIT: ReScript doesn’t support -opaque]. I promise you people who are serious about saving compile time, are writing interface files.
If PPX perf is still not acceptable then we also have great libraries like bs-json that offer powerful, compositional functions for writing JSON encoders/decoders.
Decoding is (thankfully) becoming more popular in the TypeScript world with libraries like io-ts and it’s been the norm for a long time in Elm with elm-json.
Finally–if we are scraping third-party sites then we can expect a certain amount breakage from time to time, it doesn’t mean decoders are bad. The same way that HTML parsers are not bad because websites change their DOM from time to time and break scrapers.
Thanks, I didn’t know about the perf consequences of having interface files, even though it sounds rather obvious now. But as -opaque, is it available in ReScript?
My mistake, -opaque is not available in ReScript. But as far as I know ReScript works in the same way as upstream OCaml w.r.t. looking at interface files.
EDIT: I wanted to mention one more thing: another easy way to speed up builds especially in CI is to check in ReScript JS outputs to the repo. ReScript will not rebuild outputs that are already present (at least last time I checked). In fact committing ReScript outputs has been a recommendation for a long time.
I didn’t know that either Isn’t committing ReScript outputs basically caching? Well, I guess, if the output is deterministic, there’s no harm in that. The only potential problem I see, off the top of my head, is where you’ve upgraded ReScript but haven’t rebuilt your project, which is a rather strange moment to commit anyway (and rebuilt can be enforced by npm hooks).
Yeah, you could look at it as basically caching. ReScript compiler output is indeed deterministic (assuming that projects are locking to a specific version of bs-platform). Indeed, when upgrading bs-platform, make sure to -clean-world then -build-world.

 . Crashes were really a large concern before the introduction of ReScript and
. Crashes were really a large concern before the introduction of ReScript and  Isn’t committing ReScript outputs basically caching? Well, I guess, if the output is deterministic, there’s no harm in that. The only potential problem I see, off the top of my head, is where you’ve upgraded ReScript but haven’t rebuilt your project, which is a rather strange moment to commit anyway (and rebuilt can be enforced by npm hooks).
Isn’t committing ReScript outputs basically caching? Well, I guess, if the output is deterministic, there’s no harm in that. The only potential problem I see, off the top of my head, is where you’ve upgraded ReScript but haven’t rebuilt your project, which is a rather strange moment to commit anyway (and rebuilt can be enforced by npm hooks).