First of all, thanks to all the contributors of rescript-vscode extension for your great work!
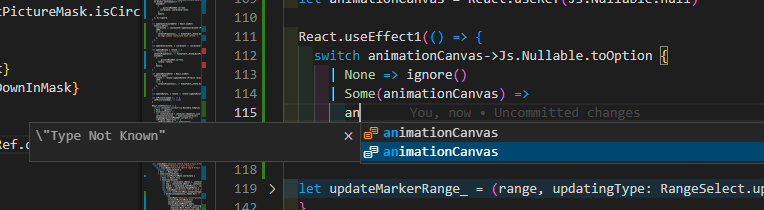
I find this after upgrading my vscode extension to 1.3.0, i don’t save my file, but get auto completing of the variable animationCanvas, although without type definition for now. Did the core team already start to write the realtime auto completing part of the rescript-vscode extension?


Thanks for bringing this up! I’ll try and do a summary of the work on autocomplete @cristianoc has been doing, because it’s quite cool (and I’m personally very excited about it). What it means now + going forward. My explanation is a bit pseudo, but hoping it’ll do.
This text ended up a bit long, so for anyone short on time:
TLDR; This improves accuracy and reliability of autocomplete by a lot already, and will open up for cool features going forward. @cristianoc is a wizard  .
.
How autocomplete used to work
Previously, the autocomplete functionality would walk backwards through the raw file text from wherever you trigger it, and try to figure out what it is you’re trying to do completion on. Example: someVariable.s ← it could figure out that there’s a . to the left of what you’ve typed, which means you’re accessing a record field, which in turn means we can look for what type someVariable has (as soon as the compiler has successfully compiled), and return all the fields of that type to autocomplete. This works well enough in the simple cases.
Notice though that we’re essentially trying to understand the ReScript code you write ourselves, without help of any ReScript tools (like the parser). This essentially means that while it works well for the simplest cases, as soon as we have more advanced cases, we’re slowly reinventing the actual ReScript parser, but in a worse and much harder way 
How it works now and the benefits that bring
What @cristianoc has done is he’s removed that standalone mini parser, and instead integrated the real ReScript parser. Instead of us moving backwards from where your cursor is to try and figure out the context, the parser will parse the entire document and we can just make our way through the AST to where your cursor is located. The ReScript parser is very good at parsing broken sources, which means that we can find the correct context in the absolute majority of cases.
Now that we can use the parser to figure out the real context we’re in when autocompleting (context == for example “we’re accessing a record field”), we’ll get a much more granular understanding of what you’re trying to complete, and where you’re trying to complete it (where == “oh I’m in a switch branch” for example). And, as we have access to the full AST from the parser for the entire file, we get a number of benefits immediately:
- We now know whether you’re trying to complete for a value or a type, because we know what syntactical context you’re in. This means we can clean up the things you get back from autocomplete - if you’re completing in a position that can only take a type, like a type annotation, we only return types as you autocomplete. And the same goes for values if you’re in a position that can only take values.
- Keeping track of all variables and bindings in scope is now much much easier and sustainable, which means we can return them as well when autocompleting. This is because they’re easy to pick up as we move through the AST towards where your cursor is located, and the parser does all of the heavy lifting for us. Compare this to the old way of parsing ourselves, we’d essentially need to make our mini parser understand the same things the real parser does (what does let assignments look like? Destructuring? Labelled arguments, regular arguments…? etc).
- Finally, we can now also complete the variables/bindings you write even before they’re saved, like @Mng12345 shows in the last screenshot. We just won’t know their type until you actually save (which you can see by it saying “Type Not Known” in the details view). This especially helps when working with broken sources that would be a syntax error if you try to save them, like the switch branch in the screenshot (that’d be a syntax error until you’ve actually written the identifier).
You’ll hopefully find that the accuracy and reliability have improved a lot in autocompleting. With that said though, this is a big refactor, so please report issues on the repo if you find contexts where you expect to get autocomplete but don’t, or where you get the “wrong” completion context. We’ve likely missed finding a few contexts and need help figuring out which they are.
What it enables for the future
This makes experimentation with more advanced autocomplete much easier in the future. Now that we get help from the parser to do the heavy lifting (figuring out the context we’re in as we’re completing), we can start experimenting with for example type based contextual completing. An example:
If someProp here is a variant type someProp = SomeValue | AnotherValue | SomethingElse, <SomeComponent someProp= could complete to the variant members, because we can now understand that you’re completing for the JSX prop someProp, and we can look up the type for that.
Another example is completing record field names when constructing a record. This is also something we’ll explore, as we now have the foundation for understanding that that’s what you’re trying to do.
Sorry, this ended up a long text, but I’m just so excited by @cristianoc work I had to share 
11 Likes
Great!!! Thank you all!.