I have some fetched data in JSON that hold string values in some fields. I currently use a bunch of if-else conditionals. After reading the [Variants Design Decisions in the docs](http://Variant Needs an Explicit Definition) I’m thinking about using variants instead of conditionals.
For example, in the JSON there is a variable shippingType that can be equal to
“NONE”
“DELIVERY”
“PICKUP”
“”
any other string
If I understand correctly, my new approach would be to create a utility function that will convert the string into a variant, and then plug it into a switch.
let getShippingTypeVariant = shippingType => {
switch(shippingType) {
| "NONE" => None
| "DELIVERY" => Delivery
| "PICKUP" => Pickup
| _ => Empty
}
};
let shippingType = getShippingTypeVariant(data.shippingType);
// then plug it into other switch logic
is this optimal or is there a better way to cast a string into a variant?
In general: if you get some data from outside your program–you always need to validate it at runtime and decode it into a type-safe value. A simple way to do this is to use ppx_decco for ReScript e.g. say you have a JSON object:
{
"shippingType": "..."
}
You would model it like this:
// Shipping.res
module Type = {
// Putting in a module for namespacing reasons
type t = None | Delivery | Pickup
let decode = json => switch json {
| "DELIVERY" => Ok(Delivery)
| "NONE" => Ok(None)
| "PICKUP" => Ok(Pickup)
| string =>
Error({
Decco.message: "Not a shipping type",
path: ".",
value: Js.Json.string(string),
})
}
}
// Represents the JSON coming over the wire
// Of course in reality has more fields
module Raw = {
@decco.decode
type t = {shippingType: string}
}
// Our domain model
// Same as above re: reality
type t = {shippingType: Type.t}
let decode = json => {
open Belt.Result
flatMap(Raw.t_decode(json), ({Raw.shippingType}) =>
map(Type.decode(shippingType), shippingType =>
{shippingType}))
}
Yes very true, I answered as if you were writing bindings to JS, but if you’re fetching things, it’s definitely wiser and safer to first decode and validate it.
Is there a solution you recommend instead? Some composable decoder library? The killer feature of decco is that it greatly reduces boilerplate. What are the downsides? Type safety?
BTW, it’d help if JSON decoders could be generated from a backend schema. I think (but I’m not sure) that ppxes like decco make it easier.
To be honest I don’t really get https://rescript-lang.org/docs/manual/latest/json#parse.
Sure it compiles to quite straight forward JS code, but it’s no better or safer than JS, what’s the point of using rescript then? If for some reason you start receiving responses that don’t follow the expected schema, you’ll get some very weird javascriptish errors down the lines, things that are not supposed to happen with Rescript. When you validate your input as soon as possible, you can leave the unsafe part at the boundary of your code and have only idiomatic undefensive rescript code inside.
I see more and more emphasis on writing rescript code that compiles to the exact same JS code you would have written manually (like in the converting from JS guide) where the parts where you start getting the benefits of rescript are labeled as optional. Using rescript over plain JS will always represent an extra hassle, it should come with rewards like type-safety, ease of refactoring, reliability, etc
Yeah, those bindings look like maybe something for interop, where you’re 100% sure you’ll get what you expect (and even then, it’s better to have guarantees than to just be sure). But if it’s just interop, why is the data serialized?
And if it’s some data from over a network, the only way that comes to mind to ensure it matches your types is when you generate your types by the schema.
The downside is that it’s a ppx. Reducing boilerplate shouldn’t come at a cost of a big opaque and slow system. See Rust for example.
Indeed. The proper way of doing this is either having a schema and a proper parsing for it (like Clojure’s transit) directly into the final representation you’ll use, plus proper data migrations, or not doing it at all and use https://rescript-lang.org/docs/manual/latest/json#parse and avoid the perf, compilation and mental overhead.
Either you want zero cost, or you want the extra overhead to be worth the bang for the buck. An encoder/decoder solution that’s halfway there, with no migration (and thus no actual safety across time, with the bad illusion of safety), and where user is supposed to do a second ad-hoc mini-parsing step by piggy backing on a parsed json into the proper data structure, makes no sense. We like “good enough” solutions but in this case this half-way solution isn’t good enough at all.
The point of ReScript is to ship polished, great looking product that’ll turn heads. Type safety is a great way to speed things up, but is not a crusade. See my answer above; if you’re transferring data that doesn’t require migration, then why are we even talking about json encoding/decoding?
That’s the entire point of the external interop system since the beginning.
We’ve always tried to mitigate the extra hassle as much as we could. Plus, Most of the extra hassle has been self-imposed by some folks and are not necessary. But to stay on topic, consider that:
Type safety: only on a very basic level.
Ease of refactoring: has nothing to do in this in either case. Actually less breakage to refactor the raw parse solution.
Reliability: again, where’s the schema? Where’s the data migration? If your backend changed data, how is the front-end handling it? What if you upgrade ReScript and some internal representations changed? What are you gonna deserialize now? Are you sure Decco even helps you think in that direction? Etc.
The basic scenario here is that we have data coming in from the network. I think we all agree that data from the network needs to be validated. My suggestion is:
JSON string coming from network -> parse into Js.Json.t -> decode into Raw.t -> transform into higher-level domain t
Now to be honest, even a nice RPC system with a facility for proper schema evolution, like say Thrift or GraphQL, only gives types with a limited level of power. If we take advantage of ReScript features like variants, then chances are really good that we’ll need to write transformation functions from the lower-level GraphQL (e.g.) types to a higher-level and safer variant type. This is not the illusion of safety, it’s just another level of encoding/decoding, which is a significant part of most programs anyway.
Decoding raw data into safer higher-level data is always a good idea; sometimes the tools we have to do that are rough and half-baked, but we can build on the type safety guarantees they offer.
Type safety is not a goal on its own, just a means to an end. The safety must be judged with respect to its own set of run-time errors. We like to think of code as safe or un-safe. Opposites on a spectrum. But often that’s not true. For instance if you query a graphql server, “un-safe” raw data is coming in over the wire, but at the same time you know the exact shape/spec of the response (safe). It has intuitive appeal to say you either have safe or unsafe data. And that might be the case in certain situations, but more likely is that data from a request is both safe and unsafe.
Writing decoders is a lot of effort, the wins are not really clear to me. Even if you auto-generate them, they still allocate a lot, are slow and increase js payload size. If you deal with completely random data, then it might make sense to really start parsing your data. But that’s a very niche use-case. Keep it simple and don’t transform your data through three different passes?
I get the attraction of keeping things simple/fast/zero-cost. You don’t have to use decoders. Just assume the JSON is the right shape and use it directly. Catch any exceptions that might get thrown. But also remember that some things like property accesses won’t throw exceptions for missing properties, they’ll return undefined. So maybe handle those specially using option types.
Now you have all these special rules that are encoded implicitly throughout the code. The possible error pathways aren’t reflected in the types. It makes it difficult to refactor and change code. This is what it means to lose type safety. I know that type safety is not a goal, just a means. But the ability to change code quickly and safely without breaking it, is a goal. And that’s what type safety enables.
On the other hand, performance and small bundle size is not a goal on its own; it is also a means to an end (good user experience). The user may be happier with a slightly heavier app that can guarantee no runtime crashes. And developers may also be happier with apps that don’t set off pagers. It’s all trade-offs
My 2 centavos: decoders give you the ability to actually trust your types. To make away with defensive programming (which might as well add more bloat to your bundle than decoders) and not be afraid of crashes or, worse, sublte bugs in unexpected places.
There’s also a bonus of having a specific place to deal with data errors and degrade gracefully (again, as opposed to doing it all over your app).
No matter how thorough your decoders are, they will do some assumptions at some point. Just consider any insane (but really common) use-case of having enormous monolithic REST endpoints, with completely wild (non-)specifications.
Let’s break down a very real, actual existing project and try to access data from existing endpoints. If this doesn’t get the point across, there is no point continuing this conversation.
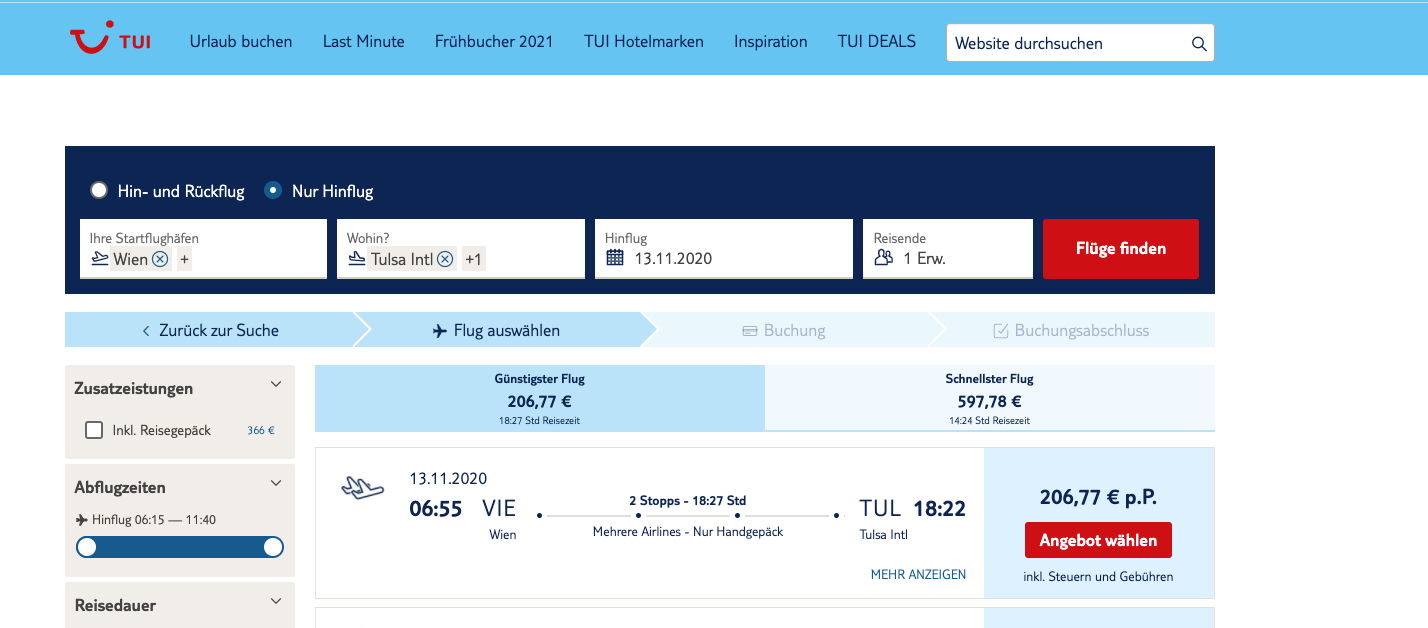
TUI.com has a really big search API for looking for vacation offers. Let’s assume I am a user that tries to find the best offers for a travel from Vienna to Tulsa:
First of all, finding out the spec, let alone going through all the organizational hierarchies within TUI to get to a single person who can tell you with 100% confidence what the actual spec is (in reality, nobody knows what they are doing, we are all in the impression that folks have a clear spec on their endpoints, reality reflects a different state, I am afraid).
Okay, so the strategy would be to “figure out the spec ourselves” by querying some endpoints and figuring out some system:
“Ah, this seems like a travel location structure”
“oh, and there are some coupon structures”
“seems like this search uses all those prev defined location structures in the target_locations attribute”
So you have been spending probably days to figure out your perfect types. Now you generate an INSANE amount of code via ppxes, first of all, completely wrecking our wonderful compile times, because these ppxes will cost you a lot of computation power on each file change, depending on how often you use the ppx in different files. We have seen massive additional compilation times caused by graphql_ppx btw.
Second of all, all this code will opaquely translate into even more massive amounts of JS code. And the best part: Most of the data in this massive 12k lines json object is absolutely useless. We only need some small fraction of it (yes, graphql yada yada, but this is an old project, and we are all dealing with legacy code / badly designed rest endpoints in 80% the cases, at least in Europe).
We are not even sure if our assumptions were correct! It’s completely ridiculous. Your coworkers will go in the code and be like “yeah we got all our types in place, so we are 100% safe”, which certainly is not true. It’s even worse, because we have wasted so much of our valuable time finding out the right structure (because through organizational reasons we can’t “just generate our schema”).
BTW the idea of validating types during runtime are not new. There are things like Flow runtime or Flow tcomp, or TypeScript runtypes. Guess what? These things don’t find any adoption because it’s mostly an intellectual exercise that can’t withhold a real world scenario in an all applicable manner or only work for very small scoped / niche project organizations… graphql is probably the most realistic system that could make “typed interfaces” work, but this of course also comes with drawbacks.
Conclusion
So what I am trying to say is that “just spec’ing your endpoints and generate the types”, whereas the UI is based on structural typing (therefore having an infinite amount of permutations of different record types), is an unrealistic goal, and we really think that skipping the whole type spec & generation part and instead go into our assumption based system that gets fine-tuned as we find errors in our integration / acceptance tests, is a way more realistic and easier way to handle the application boundaries. It’s also way easier for like 90% of the projects to adopt ReScript and enjoy all the other features that actually make ReScript enjoyable.
I hope you understand what I am saying. Seriously, whoever thinks that this is something any newcomer should do by default when coming into the ReScript community should probably do some consulting work and dive into different projects and organizations to get a clearer picture of how everyone is building their systems.
Decoders can be an optional solution decided case by case … like companies that set their goals to have fully spec’ed and fully type safe communication between client and server. Those companies that require 100% certainty and design their systems that way, and are willing to take those extra computational costs and are fine with certain bad UX scenarios (like slow loading UI etc).
I used the graphql_ppx for some smaller deployed projects (namely leiwand-kochen.at and diemagischezehn.at) to get an idea on its usage with different CMS platforms. Most of the time I am dealing with REST endpoints though, so I can’t really say anything about larger GraphQL based apps.
If you are referring to my statements regarding compilation times w/ 3rd party ppxes, i once published a benchmark-script for ReScript based projects and tried it on different open source projects (such as pupilfirst) that lead to my observations.
Feel free to try it on your own project. It’s not specifically aiming for graphql_ppx, but for ppxes in general. The more you use, the slower your build.